%20{%20.cls-1%20{%20fill:%20%23fff;%20}%20}%20%3c/style%3e%3c/defs%3e%3cg%20id='Layer_1-1'%20data-name='Layer%201'%3e%3cg%20id='Layer_1-1'%20data-name='Layer%201-1'%3e%3cpath%20class='cls-1'%20d='m220.77,35.74c2.97,0,3.62,1.09,3.41,3.84-1.09,18.77-14.64,37.69-32.18,43.57-5.87,1.96-12.32,2.83-18.48,3.12-12.61.43-25.23.14-37.84.14-1.59,0-3.19.07-4.71.29-6.09.94-10.22,5.65-10.08,11.53.14,5.87,4.78,10.8,10.87,11.09,5.94.29,11.96-.07,17.9.22,13.77.72,23.78,7.54,29,20.59,8.12,20.22-6.6,42.7-27.98,43.06-11.24.14-22.54.07-33.78.07-8.41,0-10.73,1.88-12.69,10.15-.94,3.77-1.74,7.61-3.04,11.31-6.02,17.11-17.9,27.18-35.59,29.07-9.64,1.01-19.5.14-29.79.14,2.25-10,4.35-19.5,6.52-29,1.88-8.19,3.84-16.31,5.58-24.5,3.26-15.01,13.48-23.7,28.49-23.85,13.77-.14,27.47-.07,41.25-.22,5.44-.07,9.64-3.19,11.09-7.97,1.38-4.35-.07-9.79-3.99-12.25-2.1-1.3-4.78-1.96-7.25-2.32-7.83-1.09-15.87-.94-23.41-2.97-19.21-5-31.53-22.54-30.95-42.48.58-19.93,14.35-37.11,33.27-41.46,3.26-.72,6.67-1.09,10-1.09l114.39-.07h0Z'/%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
· Fabian Schreuder · Data Science Projects · 5 min read
PCOS Prediction Using Machine Learning: A Comprehensive Analysis
Building and evaluating machine learning models to predict Polycystic Ovary Syndrome (PCOS) using clinical and biochemical features, achieving high accuracy for early diagnosis.
Polycystic Ovary Syndrome (PCOS) is a prevalent endocrine disorder impacting millions of women globally. Despite its commonality, up to 70% of cases remain undiagnosed, often due to complex and varied symptoms that overlap with other conditions. This diagnostic challenge can delay treatment and increase risks for long-term health issues like infertility, type 2 diabetes, and cardiovascular disease.
In a recent project, my team and I explored how Artificial Intelligence (AI) could help address this challenge. Our goal was clear: Identify the key health factors most strongly associated with PCOS and build accurate predictive models to aid in early detection.
The Challenge: Untangling PCOS Complexity
Diagnosing PCOS isn’t straightforward. There’s no single definitive test, and diagnosis relies on a constellation of symptoms, blood tests, and ultrasounds, leading to variability between clinicians. Symptoms themselves vary widely among individuals. Could machine learning help identify consistent patterns within complex patient data to improve diagnostic accuracy and potentially reduce reliance on invasive tests?
The Data and Our Approach
We utilized a publicly available dataset from Kaggle, originally collected across 10 hospitals in Kerala, India. This dataset contained information for 541 individuals, including demographic details, physical measurements, and clinical test results across 45 features. The target variable was binary: PCOS (Y/N).
Data Preprocessing:
Before modeling, we performed essential preprocessing steps:
- Handling Missing Values: Columns like ‘BMI’, ‘FSH/LH’, and ‘Waist:Hip ratio’ had significant missing data, which we recalculated using existing related features (Weight, Height, FSH, LH, Waist, Hip). Other missing continuous values were imputed using the mean, and missing categorical values with the mode.
- Normalization: Numerical features were normalized to ensure scale didn’t disproportionately influence the models.
- Data Splitting: We used an 80/20 train-test split (with a fixed seed for reproducibility) to train our models and evaluate their performance on unseen data.
We decided to implement and compare two distinct classification algorithms using the KNIME Analytics Platform:
- Random Forest (RF): Chosen for its ability to handle complex, non-linear relationships, manage mixed data types effectively, and provide inherent feature importance rankings. Its ensemble nature also makes it robust against overfitting compared to single decision trees.
- Logistic Regression (LogR): Selected as a complementary approach due to its strong interpretability (coefficients directly relate to the odds of PCOS), suitability for binary classification, and lower risk of overfitting on smaller datasets. We incorporated Laplace (L1) regularization to aid feature selection and manage potential multicollinearity.
AI Approach 1: Random Forest - Power and Performance
The Random Forest model was trained on the preprocessed data. Its performance on the test set was evaluated using standard metrics:
- Accuracy: 95.4%
- Precision: 95.1%
- Recall (Sensitivity): 98.7%
- Specificity: 87.1%
These results indicate a high degree of overall accuracy. The model demonstrated excellent recall, meaning it was very effective at identifying individuals who actually had PCOS. Its precision and specificity were also strong, showing it was generally reliable in its predictions.
(Note: We aimed to further interpret the RF model using SHAP values to understand feature contributions, but encountered technical challenges implementing this within the KNIME environment during the project timeframe.)
AI Approach 2: Logistic Regression - Clarity and Insights
The Logistic Regression model provided a different perspective. Its performance was also robust:
- Accuracy: 92.6%
- Precision: 91.7%
- Recall (Sensitivity): 98.7%
- Specificity: 77.4%
While slightly less accurate overall than the Random Forest, LogR achieved the same high recall. Its primary advantage lies in interpretability. By examining the model coefficients, we could directly identify the factors that had the most significant statistical association with PCOS presence in this dataset:
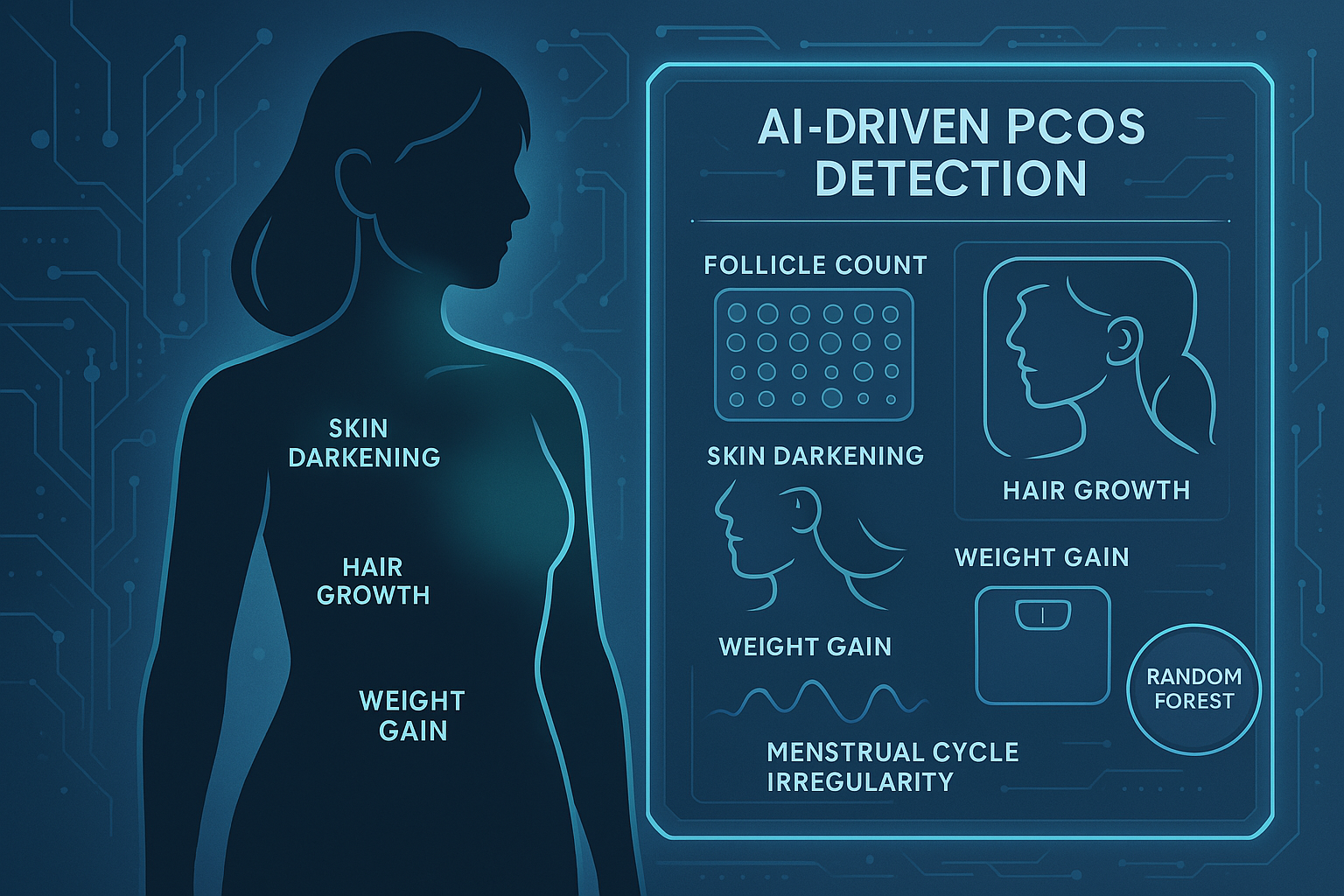
- Follicle No. (R): Negative association (Coefficient: -5.46, p < 0.001)
- Cycle(R/I) (Regular/Irregular): Negative association (Coefficient: -1.06, p = 0.03)
- Skin darkening (Y/N): Negative association (Coefficient: -1.05, p = 0.001)
- Hair growth (Y/N): Negative association (Coefficient: -0.92, p = 0.01)
- Weight gain (Y/N): Negative association (Coefficient: -0.89, p = 0.01)
(Note: The negative coefficients suggest that, based on the model scale and baseline, the presence of these factors, encoded likely as 1 vs 0 baseline, increased the log-odds of having PCOS). These findings align with known clinical indicators of PCOS.
Model Showdown: Accuracy vs. Interpretability
| Performance Metric | Random Forest (%) | Logistic Regression (%) |
|---|---|---|
| Accuracy | 95.4 | 92.7 |
| Precision | 95.1 | 91.7 |
| Recall | 98.7 | 98.7 |
| Specificity | 87.1 | 77.4 |
The Random Forest clearly demonstrated superior predictive performance, particularly in correctly identifying negative cases (higher specificity). However, the Logistic Regression model provided easily interpretable insights into which factors were driving the predictions, a crucial aspect in healthcare applications.
Key Findings and Potential Impact
This project successfully demonstrated that machine learning models, particularly Random Forest, can predict PCOS presence with high accuracy based on readily available clinical and demographic data. Logistic Regression complemented this by highlighting key predictive factors like follicle count, cycle irregularity, skin darkening, excess hair growth, and weight gain, confirming their strong association with the condition.
The potential impact is significant:
- Earlier Diagnosis: AI tools could act as decision support systems, helping clinicians identify at-risk individuals sooner.
- Improved Outcomes: Prompt diagnosis allows for earlier intervention, potentially mitigating long-term health risks.
- Resource Optimization: AI could potentially streamline the diagnostic process.
However, critical considerations remain. The model was trained on data from a specific region (Kerala, India), raising questions about generalizability. Algorithmic bias is a concern if training data doesn’t reflect the diverse population affected by PCOS. Ethical use requires keeping humans-in-the-loop, using AI as a supportive tool, not a replacement for clinical judgment.
Reflections and Future Directions
This project was a valuable exercise in applying classification algorithms to a real-world healthcare problem. It underscored the trade-offs between model complexity/accuracy (RF) and interpretability (LogR). We also navigated the practical challenges of data preprocessing and tool implementation (like the SHAP value issue in KNIME).
Future work could involve:
- Implementing SHAP value analysis for the Random Forest model.
- Fine-tuning model hyperparameters for potentially better performance.
- Exploring other advanced ML algorithms.
- Validating the models on more diverse, larger datasets from different populations.
Conclusion
Our exploration showed the promising potential of AI and machine learning in enhancing the detection and understanding of PCOS. By carefully selecting models, preprocessing data diligently, and comparing different approaches, we can build tools that offer both high predictive power and valuable clinical insights, ultimately aiming for better health outcomes for women affected by PCOS.